Реализация приоритетной очереди на основе различных структур данных и ее применение для построения остовного дерева графа с помощью алгоритма Крускала
- Постановка задачи
- Руководство пользователя
- Руководство программиста
- Заключение
- Литература
##Постановка задачи
- Разработать статические библиотеки, реализующие слудующие структуры данных:
- d-куча;
- бинарное поисковое дерево;
- просматриваемая таблица;
- упорядоченная таблица;
- приоритетная очередь, основанная на d-куче;
- приоритетная очередь, основанная на бинарном поисковом дереве;
- приоритетная очередь, основанная на упорядоченной таблице;
- разделенные множества.
- Написать тестирующую программу для каждой структуры данных с помощью Google C++ Testing Framework.
- Написать приложение для демонстрации работы d-кучи (пирамидальная сортировка).
- Написать приложение для демонстрации работы приоритетной очереди, основанной на d-куче (алгоритм Дейкстры):
- входные данные - связный неориентированный взвешенный граф без петель со стартовой вершиной;
- выходные данные - список расстояний до каждой вершины графа.
- Написать приложение для демонстрации работы приоритетной очереди и разделенных множеств (алгоритм Крускала):
- входные данные - связный неориентированный взвешенный граф без петель;
- выходные данные - граф, представляющий минимальное остовное дерево для исходного графа.
##Руководство пользователя
###Использование реализации алгоритма Дейкстры
####Запуск приложения и ввод данных
Программа предназначена для поиска кратчайших путей во взвешенном неориентированном графе от некоторой вершины, называемой текущей, до всех остальных вершин графа.
Для запуска приложения нужно открыть исполняемый файл sample_Dijkstra.exe.
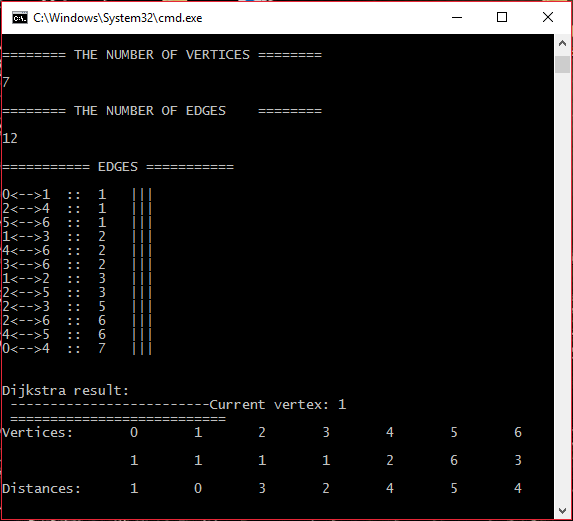
Программа попросит ввести количество вершин графа и ребра с весом. Также будет запрошен номер вершины, являющейся стартовой. Результатом будет вывод вектора, содержащего номера вершин, что предшествуют вершинам, являющимся индексами вектора, для построения дерева, позволяющего восстановить обход и вывод списка расстояний от стартовой вершины до каждой из следующих вершин в порядке возрастания номера.
####Пример:
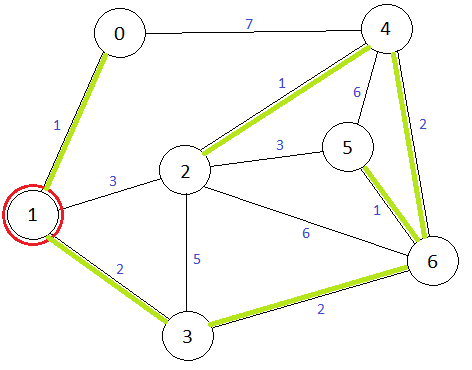
Рассмотрим граф:
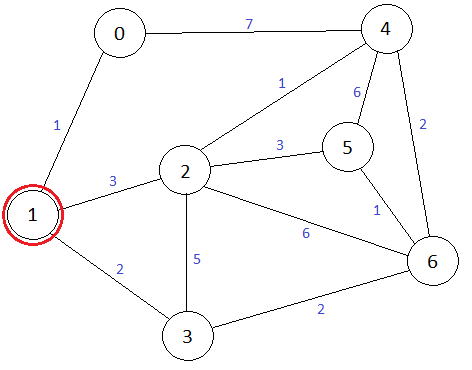
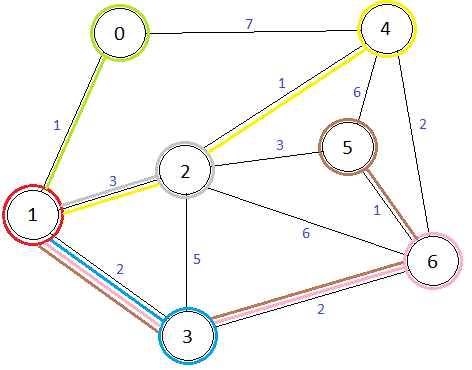
Для рассматриваемого графа алгоритм считает расстояния от вершины №1 до всех остальных вершин (ребра, через которые проходит кратчайший путь до вершины, помечены цветом этой вершины):
#####Шаг 1 Ввод количества вершин графа
#####Шаг 2 Ввод ребер и их весов
#####Шаг 3 Выбор стартовой вершины
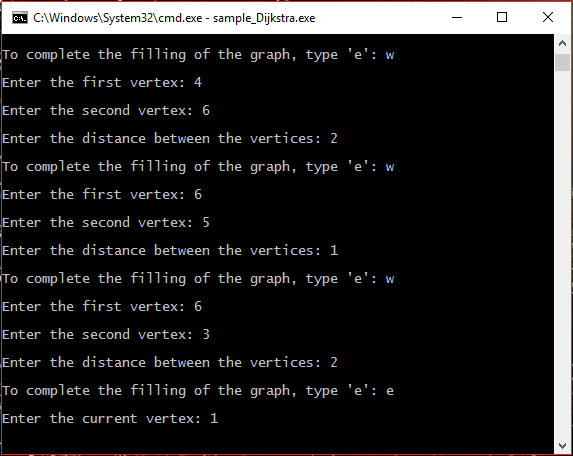
#####Шаг 4 Вывод результата и завершение работы программы
###Использование реализации алгоритма Крускала
####Запуск приложения и ввод данных
Программа предназначена для построения минимального остовного дерева для взвешенного неориентированного графа.
Для запуска приложения нужно открыть исполняемый файл sample_Kruskal.exe.
Программа попросит ввести количество вершин графа и ребра с весом. Результатом работы программы будет вывод списка ребер, составляющих минимальное остовное дерево.
####Пример
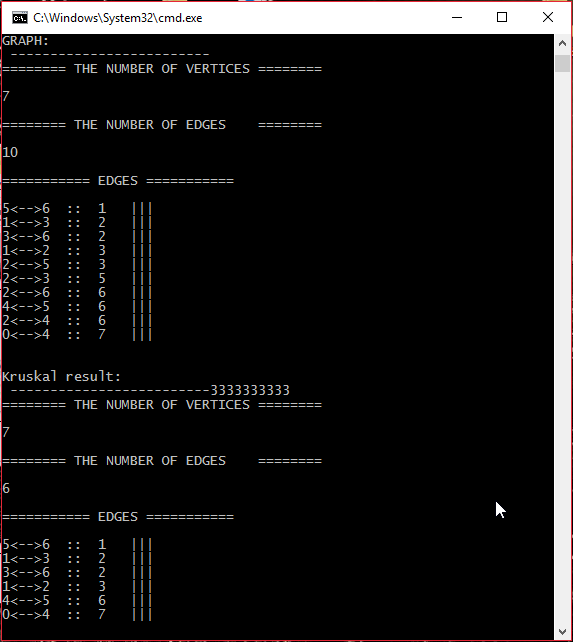
Рассмотрим граф:
Для рассматриваемого графа алгоритм строит дерево, выделенное зеленым цветом:
#####Шаг 1 Ввод количества вершин графа
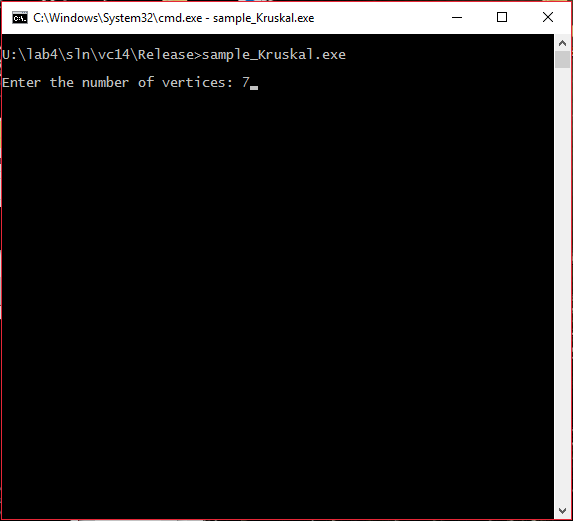
#####Шаг 2 Ввод ребер и их весов
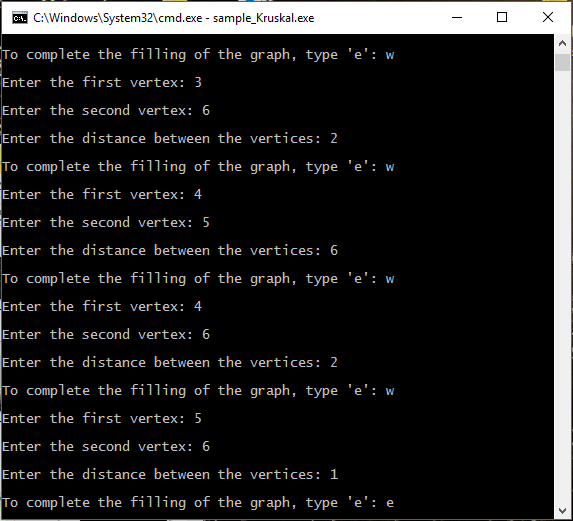
#####Шаг 3 Выбор базы для приоритетной очереди

#####Шаг 4 Вывод результата и завершение работы программы
##Руководство программиста
###Используемые технологии
В ходе выполнения работы использованы следующие технологии:
- Среда разработки Microsoft Visual Studio Community (2015).
- Фреймворк для написания автоматических тестов Google Test.
- Система контроля версий Git.
###Общая структура репозитория
Репозиторий содержит следующие директории и файлы:
gtest- библиотека GoogleTest.src- директория для размещения файлов исходноо кода.include- директория для размещения заголовочных файлов.sample- директория для размещения исходных кодов приложений.test- директория для размещения тестов.sln- директория с файлими решений (на данный момент Visual Studio 2015).Rept- директория с материалами для отчета;- Служебные файлы:
.gitignore- перечень расширений файлов, игнорируемых Git при добавлении файлов в репозиторий.
###Описание структуры решения
Решение состоит из 12 проектов:
gtest- фреймворк Google Test;d-heap_lib- статическая библиотека, содержащая объявление и реализацию шаблонного классаD_HEAP.disjoint-set_lib- статическая библиотека, содержащая объявление и реализацию шаблонного классаDISJOINT_SET.binary_search_tree_lib- статическая библиотка, содержащая объявление и реализацию классаBST.tables_lib- статическая библиотека, содержащая объявление и реализацию шаблонных классовTABLE,SCAN_TABLE,SORT_TABLE.graph_lib- статическая библиотека, содержащая объявление и реализацию классаGRAPH.priority_queue_lib- статическая библиотека, содержащая объявление и реализацию шаблонных классов приоритетных очередей, основанных на разных структурах данных.algorithms- статическая библиотека, содержащая объявление и реализацию алгоритмов для примеров.sampleDijkstra- консольное приложение для демонстрации работы алгоритма Дейкстры.sample_Kruskal- консольное приложение для демонстрации работы алгоритма Крускала.sample_d-heap- консольное приложение для демонстрации работы пирамидальной сортировки.test- консольно приложение для проверки правильности реализации классовD_HEAP,PRIORITY_QUEUE,DISJOINT_SET.
###Описание структур данных
####D-куча D-куча - завершенное d-арное дерево, содержащее набор однотипных элементов, со следующими свойствами:
- каждый узел, не являющийся листом, за исключением, быть может, одного имеет ровно d потомков. Один узел, являющийся исключением, может иметь от 1 до d-1 потомка;
- если h - глубина дерева, то для любого i = 1, ..., k-1 такое дерево имеет ровно d^i узлов глубины i;
- количество узлов глубины k в дереве глубины k может варьироваться от 1 до d^k;
- каждый узел имеет вес. Иначе говоря, каждому узлу дерева присвоен ключ такого типа данных, на котором определен порядок сравнения;
- ключ элемента, приписанного узлу i, не превосходит ключа любого из своих потомков.
#####Основные операции:
- Всплытие:
ВСПЛЫТИЕ(i){
p = (i - 1) / d;
while (i != 0 && key[p] > key[i]){ // Здесь и далее `key[]` - массив, хранящий d-кучу
ТРАНСПОНИРОВАНИЕ(i, p);
i = p;
p = (i - 1) / d;
}
}
- Погружение:
ПОГРУЖЕНИЕ(i){
с = minchild(i); // Здесь и далее minchild возвращает индекс, по которому хранится ребенок минимального веса для данного родителя
while (i != 0 && key[c] < key[i]){
ТРАНСПОНИРОВАНИЕ(i, c);
i = c;
c = minchild(c);
}
}
- Транспонирование:
ТРАНСПОНИРОВАНИЕ(i, j){
tmp = key[i];
key[i] = key[j];
key[j] = tmp;
}
- Вставка:
ВСТАВКА(x){
key[size] = x;
ВСПЛЫТИЕ(size);
size += 1;
}
- Удаление:
УДАЛЕНИЕ(i){
key[i] = key[size - 1];
size -= 1;
ПОГРУЖЕНИЕ(i);
}
- Окучивание:
ОКУЧИВАНИЕ(){
for(size_t i = size - 1; i >= 0; i--)
ПОГРУЖЕНИЕ(i);
}
- Доступ к элементу:
ПОЛУЧИТЬ(i){
return key[i];
}
####Бинарное поисковое дерево Бинарное поисковое дерево - это двоичное дерево, обладающее следующими свойствами:
- каждый узел имеет не больше двух потомков;
- любое поддерево является бинарным поисковым деревом;
- значение ключа любого узла левого поддерева меньше значения ключа корневого узла;
- значение ключа любого узла правого поддерева больше значения ключа корневого узла.
#####Основные операции:
- Поиск:
ПОИСК(key){
node = root; // Здесь и далее `root` - корневой узел дерева
while(node != 0 && node->key != key){
if (node->key > key) node = node->left;
else node = node->right;
}
return node;
}
- Поиск минимума:
МИНИМУМ(){
node = root;
while(node->left != 0)
node = node->left;
}
- Поиск максимума:
МАКСИМУМ(){
node = root;
while(node->right != 0)
node = node->right;
}
- Поиск предыдущего:
НАЙТИ_ПРЕДЫДУЩИЙ(node){
if (node->left != 0) return МАКСИМУМ(node->left);
y = x->parent;
while(y != 0 && x == y->left){
x = y;
y = y->parent;
}
return y;
}
- Поиск следующего:
НАЙТИ_СЛЕДУЮЩИЙ(node){
if (node->right != 0) return МИНИМУМ(node->right);
y = x->parent;
while(y != 0 && x == y->right){
x = y;
y = y->parent;
}
return y;
}
- Вставка:
ВСТАВКА(node){
y = 0;
x = root;
while(x != 0){
y = x;
if (node->key < x->key) x = x->left;
else x = x->right;
}
node->parent = y;
if (y == 0) root = node;
else if (node->key < y->key) y->left = node;
else y->right = node;
}
- Удаление:
УДАЛЕНИЕ(key){
node = МИНИМУМ();
if (node->parent == 0) {
if (node->right_ == 0) {
root = 0;
delete node;
}
root = node->right;
root->parent = 0;
node->right = 0;
delete node;
}
node->parent->left = node->right;
node->right = node->parent = NULL;
delete node;
}
####Таблицы
#####Просматриваемые таблицы Таблица - динамическая структура данных, хранящая однотипные элементы. Записи хранятся в векторе памяти в порядке добавления (добавление производится в конец таблицы). При удалении записи просиходит перепаковка (сдвиг всех записей ниже текущей на одну позицию вверх).
Основные операции:
- Проверка на пустоту:
ПУСТОТА(){
return ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ == 0;
}
- Проверка на полноту:
ПОЛНОТА(){
return ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ == РАЗМЕР_ТАБЛИЦЫ;
}
- Вставка:
ВСТАВИТЬ(record){
if (!ПОЛНОТА()){
recs[ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ] = record; // Здесь и далее `recs` - вектор, хранящий записи в таблице.
ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ += 1;
}
}
- Удаление:
УДАЛЕНИЕ(key){
if (!ПУСТОТА()){
record = recs[0];
tmp = 0;
while(КЛЮЧ(recs[tmp]) != key && tmp <= ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ)
tmp += 1;
if (tmp > ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ) return;
recs[tmp] = recs[ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ - 1];
recs[ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ - 1] = 0;
ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ -= 1;
}
}
- Поиск:
НАЙТИ(key){
if (ПУСТОТА()) return;
tmp = 0;
while(КЛЮЧ(recs[tmp]) != key && tmp <= ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ)
tmp += 1;
if (tmp > ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ) return 0;
return recs[tmp];
}
- Доступ:
ПОЛУЧИТЬ(i){
return recs[i];
}
#####Упорядоченные таблицы Упорядоченная таблица - это просматриваемая таблица, данные в которой отсортированы по невозрастанию/неубыванию ключей. Причем при вставке и удалении происходят перепаковки.
Основные операции:
- Проверка напустоту (см. просматриваемые таблицы).
- Проверка на полноту (см. просматриваемые таблицы).
- Вставка:
ВСТАВИТЬ(record){
if (ПОЛНОТА()) return;
НАЙТИ(КЛЮЧ(record), addr);
for (int i = ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ; i >= addr && i > 0; i--)
recs[i] = recs[i - 1];
ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ += 1;
recs[addr] = record;
}
- Удаление:
УДАЛИТЬ(key){
if (ПУСТОТА()) return;
addr = 0;
if (НАЙТИ(key, addr) == 0) return;
delete recs[addr];
for (size_t i = addr; i < ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ - 1; i++) {
recs[i] = recs[i + 1];
}
ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ -=1;
}
- Поиск:
НАЙТИ(key, & addr){
left = 0;
right = ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ - 1;
mid;
while (left <= right){
mid = left + (right - left) / 2;
if (key < КЛЮЧ(recs[mid])) {
right = mid - 1;
addr = left;
}else if (key > КЛЮЧ(recs[mid])) {
left = mid + 1;
addr = left;
}
else{
addr = mid;
return recs[mid];
}
}
return 0;
}
####Приоритетная очередь Приоритетная очередь — это динамическая структура данных, содержащая элементы, каждый из которых имеет определенный приоритет. Элемент с более высоким приоритетом находится перед элементом с более низким приоритетом. Если у элементов одинаковые приоритеты, они располагаются в зависимости от своей позиции в очереди.
Основные операции:
- Вставка элемента:
ВСТАВИТЬ(x). - Удаление старшего элемента:
УДАЛИТЬ(). - Получение старшего элемента:
ПОЛУЧИТЬ(). - Проверка на пустоту:
ПУСТОТА(). - Проверка на полноту:
ПОЛНОТА().
#####Реализация операций на разных структурах данных ######D-куча
- Вставка элемента:
ВСТАВИТЬ(x);
- Удаление старшего элемента:
УДАЛИТЬ(0);
- Получение старшего элемента:
return ПОЛУЧИТЬ(0);
- Проверка на пустоту:
return КОЛИЧЕСТВО_ЭЛЕМЕНТОВ == 0;
- Проверка на полноту:
return КОЛИЧЕСТВО_ЭЛЕМЕНТОВ == МАКСИМАЛЬНЫЙРАЗМЕР;
######Бинарное поисковое дерево
- Вставка элемента:
ВСТАВИТЬ(x);
- Удаление старшего элемента:
УДАЛИТЬ(КЛЮЧ(МИНИМУМ()));
- Получение старшего элемента:
return КЛЮЧ(МИНИМУМ());
- Проверка на пустоту:
return КОЛИЧЕСТВО_УЗЛОВ == 0;
- Проверка на полноту:
return КОЛИЧЕСТВО_ЭЛЕМЕНТОВ == МАКСИМАЛЬНЫЙРАЗМЕР;
######Упорядоченные таблицы
- Вставка элемента:
ВСТАВИТЬ(x);
- Удаление старшего элемента:
УДАЛИТЬ(КЛЮЧ(ПОЛУЧИТЬ(0)));
- Получение старшего элемента:
return КЛЮЧ(ПОЛУЧИТЬ(0));
- Проверка на пустоту:
return ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ == 0;
- Проверка на полноту:
return ТЕКУЩЕЕ_КОЛИЧЕСТВО_ЗАПИСЕЙ == РАЗМЕР_ТАБЛИЦЫ;
####Разделенные множества Разледенные множества - абстрактный тип данных, предназначенный для представления коллекции k попарно непересекающихся можеств.
Основные операции:
- Создать:
СОЗДАТЬ(x){
if (U[root] != -1) return; // Здесь и далее `U[]` - массив для хранения универса
U[root] = root;
ТЕКУЩЕЕ_КОЛИЧЕСТВО_МНОЖЕСТВ += 1;
}
- Объединить:
ОБЪЕДИНИТЬ(x, y){
if (U[x] == -1 || U[y] == -1) return;
U[MAX(x, y)] = MIN(x, y);
ТЕКУЩЕЕ_КОЛИЧЕСТВО_МНОЖЕСТВ -= 1;
}
- Найти (позволяет определить имя корня множества):
НАЙТИ(x){
if (U[x] == -1) return -1;
while(U[x] != x) x = U[x];
return x;
}
###Описание алгоритмов
####Пирамидальная сортировка
#####Вход
Вектор значений.
#####Выход
Вектор, содержащий в себе значения исходного, но последние отсортированы по неубыванию.
#####Алгоритм
- Вектор значений переписывается в d-кучу.
- Просматривается минимальный элемент кучи и кладется в результирующий вектор.
- Минимальный элемент д-кучи меняется с последним.
- Декрементируется размер д-кучи.
- Погружение нулевого элемента.
- Если размер кучи положителен, переход к п.2, иначе алгоритм завершается.
Таким образом, вощвращаемый вектор значений будет отсортирован по неубыванию.
####Алгоритм Дейкстры
#####Вход
Задается взвешенный (каждому ребру присвоено значение веса) связный (из любой вершины можно добраться до всех остальных вершин) граф. Задается стартовая вершина.
#####Выход
При окончании работы алгоритма выходом является пара массивов, содержащих:
- список предшествующих вершин для текущих, являющихся индексами, для построения дерева обхода;
- список расстояний от стартовой вершины до всех остальных.
#####Алгоритм
- Задается взвешенный граф из n вершин.
- Задается стартовая вершина CUR.
- Создается вектор для отметки посещения вершины V (все элементы зануляются, V[CUR] = CUR).
- Создается результирующий вектор расстояний DIST (все элементы устремлены в бесконечность, DIST[CUR] = 0).
- Создается приоритетная очередь, в которую кладется расстояние от текущей вершины до неё же.
- Пока очередь не пуста:
- Вынимается минимальный элемент.
- Если метка вынутого элемента больше метки, хранящейся в массиве DIST, переход к следующему шагу.
- По всем ребрам от текущей вершины: Если результирующее расстояние от смежной вершины больше, чем результирующее расстояние до вынутой в пункте 6.1 вершины в сумме с меткой ребра, вынутогов пункте 6.3, выполняем:
- В вектор V по номеру смежной вершины кладется значение вершины, вынутой на этапе 6.1.
- В вектор DIST по номету смежной вершины пишется новое значение расстояния, равное сумме результирующего расстояния до вынутой в пункте 6.1 вершины и меткои ребра, вынутогов пункте 6.3.
- Обработанное ребро кладется в очередь.
Результатом работы алгоритма становится вектор расстояний до каждой вершины графа (DIST) и вектор обхода вершин графа для получения указанных значений (V).
####Алгоритм Крускала
#####Вход
Задается взвешенный (каждому ребру присвоено значение веса) граф.
#####Выход
Результатом работы алгоритма является вывод графа:
- дерево, если исходный граф был связен;
- лес, если исходный граф не был связен. Количество деревьев равно количеству компонент связности исходного графа.
#####Алгоритм
- Задается взвешенный неориентированный граф из n вершин.
- Создается приоритетная очередь из ребер графа (приоритет по метке ребра).
- Содрается коллекция из множества вершин.
- Вынимается ребро из приоритетной очереди.
- Если вынутые вершины находятся не в одной коллекции:
- Объединяются коллекции, содержащие данные вершины.
- Вынутое ребро добавляется в результирующий набор ребер.
- Если количество коллекций вершин больше количества компонент связности графа, переход к пункту 4, иначе алгоритм завершается.
В результате работы алгоритма имеется набор ребер, составляющих минимальное остовное дерево данного графа.
###Программная реализация структур данных
####Схема наследования классов
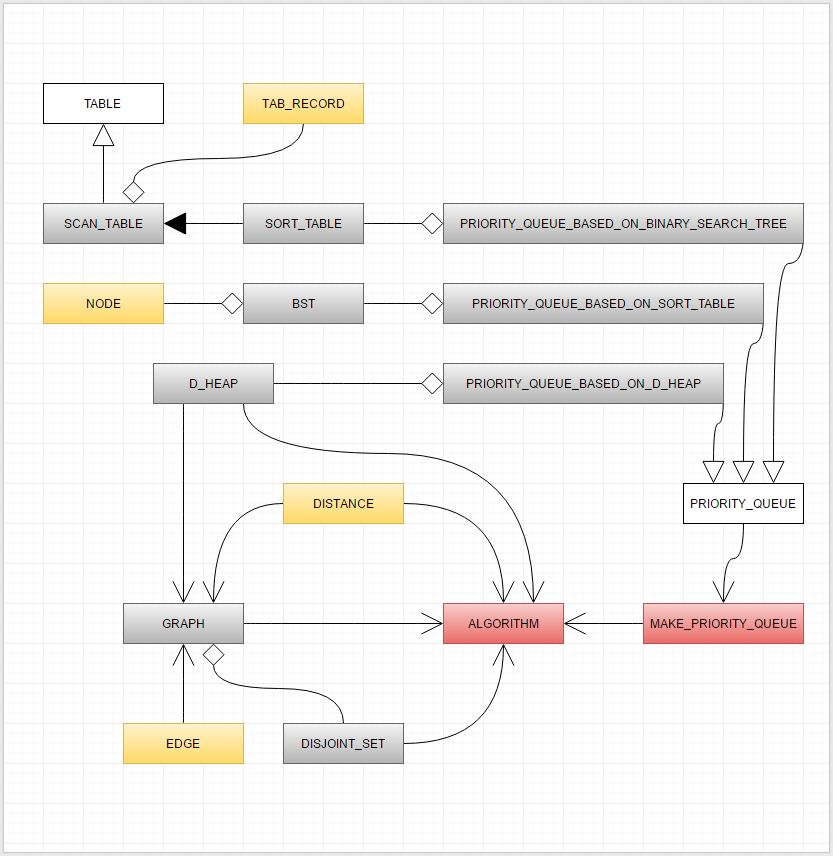
####Программная реализация d-кучи
В лабораторной работе d-куча представлена классом D_HEAP, содержащим нижеизложенные:
-
Поля:
tree_ : KeyType*- массив для хранения дерева (номер узла ассоциируется с номером ячейки массива).sizeTree_ : int- количество элементов в дереве.size_ : int- размер вектора памяти для хранения дерева.d_ : int- арность кучи.
-
Открытые методы:
D_HEAP(int, int)- конструктор. Принимает на вход стартовый размер вектора памяти для хранения d-кучи и арность.D_HEAP(const D_HEAP<KeyType>&)- конструктор копирования.~D_HEAP (void)- деструктор.operator==(const D_HEAP<KeyType>&)const- перегруженный оператор сравнения на равенство (требуется для проведения тестов).operator!=(const D_HEAP<KeyType>&)const- перегруженный оператор сравнения на неравенство (требуется для проведения тестов).getSizeTree(void)const- возвращает количество узлов, содержащихся в d-куче.getNodeKey(int)const- возврацает ключ узла, номер которого передан в качестве параметра.getSizeReservedMem(void)const- возвращает размер свободной памяти в выделенном ранее векторе памяти.getD(void)const- возвращает арность кучи.swap(int, int)- меняет местами узлы, индексы которых переданы в качестве параметров.siftDown(int)- выполняет погружение узла с индексом, указанным в качестве аргумента.siftUp(int)- выполняет всплытие узла с индексом, указанным в качестве аргумента.insert(const KeyType&, mem_rc flag = ALLOW_MEMORY_REALLOCATION_WCV, int size = 0)- производит вставку узла, переданного первым аргументом в дерево. Вторым параметром указывается правило обработки ситуации, когда вставляется узел в полное дерево:ALLOW_MEMORY_REALLOCATION_WYV- разрешить выделить дополнительную память при вставке узла в полное дерево. Размер добавляемой памяти указывается в качестве третьего параметра.ALLOW_MEMORY_REALLOCATION_WCV- разрешить выделить дополнительную память при вставке узла в полное дерево, однако третий аргумент метода в этом случае игнорируется, выделение же памяти будет таковым, что появляется место минимум под один узел, максимум под d узлов. Текущее значение выделения памяти будет таковым, чтобы выполнялись указанные условия и одно дополнительное: новый размер вектора памяти делится на арность кучи.PROHIBIT_MEMORY_REALLOCATION- запретить выделение дополнительной памяти при вставке узла в полное дерево.
deleteMinElem(void)- удаление узла с минимальным весом.deleteElem(int)- удаление узла дерева по индексу хранения в векторе памяти.heapify(void)- окучивание.getTree(void)const- возвращает вектор значений, содержащихся в векторе памяти, что хранит исходное дерево (требуется для тестирования).operator<<(...)- печать массива, хранящего значения узлов.
Класс реализован шаблонным, что позволяет хранить любого рода данные, для которых определен порядок сравнения.
####Программая реализация бинарного поискового дерева
Узел дерева представляется классом NODE, содержащим следующие поля:
KeyType data_- данные.NODE<KeyType>* left_- указатель на левого потомка.NODE<KeyType>* right_- указатель на правого потомка.NODE<KeyType>* parent_- укаазатель на родителя.
Бинарное поисковое дерево представлено классом BST, содержащим нижеизложенные:
- Поле:
root_- поле типа NODE*; указатель на корневой узел дерева.
- Методы:
getNodeForErasing(const KeyType&)- вынимает из дерева узел, который требуется удалить.recursiveErase(NODE<KeyType>*&)- удаляет дерево.copy(NODE<KeyType>*, NODE<KeyType>*)- копирует дерево.BST(void)- конструктор.BST(const BST<KeyType>& tree)- конструктор копирования.~BST(void)- деструктор.insert(const KeyType&)- вставка нового элемента в дерево.erase(const KeyType&)- удаление узла из дерева по заданному ключу.find(const KeyType&)const- поиск узла дерева, содержащего указанный ключ.findMin(NODE<KeyType>* node = NULL)const- поиск минимального элемента в дереве, корень которого передан в качестве параметра.findMax(NODE<KeyType>* node = NULL)const- поиск максимального узла в дереве, корень которого передан в качестве параметра.findPrev(NODE<KeyType>*)const- поиск узла, являющегося предыдущим по значению для текущего.findNext(NODE<KeyType>*)const- поиск узла, являющегося следующим по значению для текущего.getSize(void)const- получение количества узлов в дереве.recPostOrder(void)const- обратный обход дерева.
Класс реализован шаблонным, что позволяет хранить любого рода данные, для которых определен порядок сравнения.
####Программая реализация просматриваемых таблиц
Запись в таблице представлена классом TAB_RECORD, содержащим в качестве поля ключ с определенным отношением порядка.
База для всех таблиц представлена классом TABLE, содержащим:
- Чисто виртуальные и виртуальные методы:
isEmpty(void)const- проверка таблицы на пустоту.isFull(void)const- проверка таблицы на полноту.getCount(void)const- получение текущего количества записей.reset(void)- установка индекса навигации в стартовую позицию.goNext(void)- перевод индекса навигации на следующую позицию.isTabEnded(void)const- проверка достижения индексом навигации конца таблицы.
- Поля:
size_ : size_t- максимальный размер таблицы.count_ : size_t- количество записей в таблице.cur_ : size_t- текущая позиция (для навигации по таблице).
Просматриваемые таблицы представлены классом SCAN_TABLE, содержащим нижеизложенные:
- Методы:
SCAN_TABLE(size_t size)- конструктор (выделяет вектор памяди для хранения данных таблицы).SCAN_TABLE(const SCAN_TABLE<DataType>& table)- конструктор копирования.~SCAN_TABLE(void)- деструктор.find(const DataType&)- поиск записи с суказанным ключом.insert(const TAB_RECORD<DataType>&)- вставка новой записи.erase(const DataType&)- удаление записи из даблицы.getCurrentRecord(void)const- получение записи, закрепленной за индексом навигации.eraseCurrentRecord(void)- удаление записи, закрепленной за индексом навигации.
- Поле:
recs_ : TAB_RECORD<DataType>**- массив указателей на записи.
Класс реализован шаблонным, что позволяет хранить любого рода данные, для которых определен порядок сравнения.
####Программая реализация упорядоченных таблиц
Упорядоченные таблицы наследуются от класса SCAN_TABLE и представлены классом SORT_TABLE, содержащим нижеизложенные методы:
sort(void)- сортировка данных (требуется для конструктора преобразования типа).SORT_TABLE(size_t size)- конструктор.SORT_TABLE(const SORT_TABLE<DataType>& table)- конструктор копирования.SORT_TABLE(const SCAN_TABL<DataType>E& table)- конструктор преобразования типа.~SORT_TABLE(void)- деструктор.find(const DataType&)- переопределенный метод поиска записи с указанным ключом (используется бинарный поиск).insert(const TAB_RECORD<DataType>&)- переопределенный метод вставки новой записи в таблицу.erase(const DataType&)- переопределенный метод удаления записи из таблицы.
Класс реализован шаблонным, что позволяет хранить любого рода данные, для которых определен порядок сравнения.
####Программая реализация приоритетной очереди
Приоритетная очередь представлена базовым абстрактным классом PRIORITY_QUEUE, от которого наследуются классы PRIORITY_QUEUE_ON_D_HEAP (агрегирует в себе d-кучу), PRIORITY_QUEUE_ON_BINARY_SEARCH_TREE (агрегирует в себе бинарное поисковое дерево), PRIORITY_QUEUE_ON_SORT_TABLE (агрегирует в себе упорядоченную таблицу), содержащие следующие:
- Методы:
PRIORITY_QUEUE_ON_*(void)- конструктор (выделяет память под базовую структуру данных).PRIORITY_QUEUE_ON_*(const PRIORITY_QUEUE_ON_*<KeyType>&)- конструктор копирования.~PRIORITY_QUEUE_ON_*(void)- деструктор.getSize(void)const- получение количества элементов в очереди.isEmpty(void)const- проверка на пустоту.isFull(void)const- проверка на полноту.pop(void)- удаление элемента с наивысшим приоритетом.push(const KeyType&)- вставка элемента.back(void)const- простотр элемента с наивысшим приоритетом.
- Поля:
heap_ : D_HEAP<KeyType>*- указатель на d-кучу (для классаPRIORITY_QUEUE_ON_D_HEAP).tree_ : BST<KeyType>*- указатель на бинарное поисковое дерево (для классаPRIORITY_QUEUE_ON_BINARY_SEARCH_TREE).table_ : SORT_TABLE<KeyType>*- указатель на упорядоченную таблицу (для классаPRIORITY_QUEUE_ON_SORT_TABLE).
Классы реализованы шаблонными, что позволяет хранить любого рода данные, для которых определен порядок сравнения.
####Программая реализация разделенных множеств
Разделенные множества представлены классом DISJOINT_SET.
Узлы деревьев хранятся в массиве U_, который является некоторым универсальным множеством. Принцип формирования множеств описан в разделе описание структур данных.
Класс DISJOINT_SET содержит следующие:
- Методы:
DISJOINT_SET<KeyType>(int)- конструктор; принимает в качестве аргумента максимальное суммарное количество элементов множеств.DISJOINT_SET<KeyType>(const DISJOINT_SET<KeyType>&)- конструктор копирования.~DISJOINT_SET<KeyType>(void)- деструктор.createSet(int)- создает одноэлементное множество с элементом, указанным в качестве аргумента.uniteSets(int, int)- объединяет два множества (множества передаются номером главного элемента).findSet(int)- возвращает главный элемент множества, если элемент принадлежит какому-либо множеству, иначе -1.getNumberOfSets(void)const- возвращает текущее количество множеств (требуется для тестирования).getUniversalSet(void)const- возвращает вектор, хранящий структуру множеств (требуется для тестирования).getSet(int)const- возвращает вектор элементов, содержащихся в множестве, которое указано в качестве аргумента (множество задается главным элементом).operator<<(...)- выводит вектор, содержащий структуру множеств.
- Поля:
U_ : vector<KeyType>- хранит структуру деревьев.count_ : size_t- хранит текущее количество множеств.
Представленный набор методов достаточен для проведения тестирования корректности представления и работы класса, а также использования его в иных алгоритмах.
###Представление графа
Ребро представляется классом-сущностью EDGE. Класс содержит три открытых поля:
first: size_t.second: size_t.distance: double. Гдеfirstиsecondсодержат связываемые вершины (в порядке неубывания), аdistance- вес ребра.
Граф представлен классом GRAPH, содержащим нижеизложенные:
- Методы:
GRAPH(size_t)- конструктор.GRAPH(const GRAPH&)- конструктор копирования.~GRAPH(void)- деструктор.setDistance(size_t, size_t, double)- устанавливает ребро графа.getDistance(size_t, size_t)- возвращает вес ребра графа (0, если ребра нет).getNumOfVertices(void)- возвращает число вершин графа.eraseEdge(size_t, size_t)- удалает ребро из графа, если оно присутствует.fillGraph(void)- метод заполнения графа (вручную).createGraph(size_t, double, double)- создание графа со случайными метками ребер.getNumOfComponents(void)const- получение количества компонент связности графа.getAllEdges(void)- возвращает множество всех ребер графа.getSetOfEdges(size_t)- возвращает множество пар: смежная вершина и расстояние до неё.graphInfo(void)- вывод информации о графе.- количество вершин;
- количество ребе
- список ребер.
- Поля:
graph_ : multiset<EDGE>- хранит множество ребер для представления графа.vertices_ : size_t- хранит количество вершин графа.
##Заключение В ходе лабораторной работы были реализованы структуры данных "d-куча", "бинарное поисковое дерево", "просматриваемая таблица", "упорядоченная таблица", "приоритетная очередь" и "разделенные множества" с использованием шаблонных классов. Также написано тестирующее приложение, которое покрывает все методы, используемые в указанных классах (Все тесты успешно пройдены). Написаны консольные приложения:
- пирамидальная сортировка массива, заполняемого случайным образом;
- алгоритм Дейкстры для поиска кратчайших путей от некоторой стартовой вершины связного неориентированного взвешенного графа без петель до всех прочих с использованием приоритетной очереди, основанной на d-куче;
- алгоритм Крускала для построения минимального остовного дерева/леса неориентированного взвешенного графа без петель с использованием приоритетных очередей на базе d-кучи, упорядоченных таблиц и бинарных поисковых деревьев.
##Литература
- Кормен Т., Лейзерсон Ч., Риверст Р., Штайн К. Алгоритмы. Построение и анализ. - М.: Издательский дом "Вильямс". - 2005. - 1290с.
- Алексеев В.Е., Таланов В.А. Графы. Модели вычислений. Структуры данных: Учебник. – Нижний Новгород: Изд-во ННГУ, 2005. 307 с.