For this project, I wrote code to implement an N-Body simulation in CUDA, visualized using GLSL. The N-Body simulator is like a gravity sim resembling a solar system where planets would orbit around a star. This assignment was an exercise on the use of shared memory and how efficient it is for programs, since the last two (the Raytracer and Pathtracer) didn't explicitly focus on performance and efficiency. As always, a framework starter code was provided by our TA, Liam Boone.
The code I've written could be optimized a lot further, since it contains quite a lot of uncoalesced global memory accesses and shared memory access bank conflicts (where the threads loop through each element in shared/global memory). One way that this could be done is by launching a block of threads for every object in which each thread will only calculate the force/acceleration on that object due to a single other object in the scene. A Parallel reduction could then be performed to find the total force/acceleration on that body. However, it is impossible to predict what the effect will be on performance without performing performance profiling using NSight, which is out of bounds for me.
Nevertheless, using this code, I was able to witness a HUGE speedup when using shared memory as opposed to global (53 fps vs. 243).
Flocking:
Gravity Simulation:
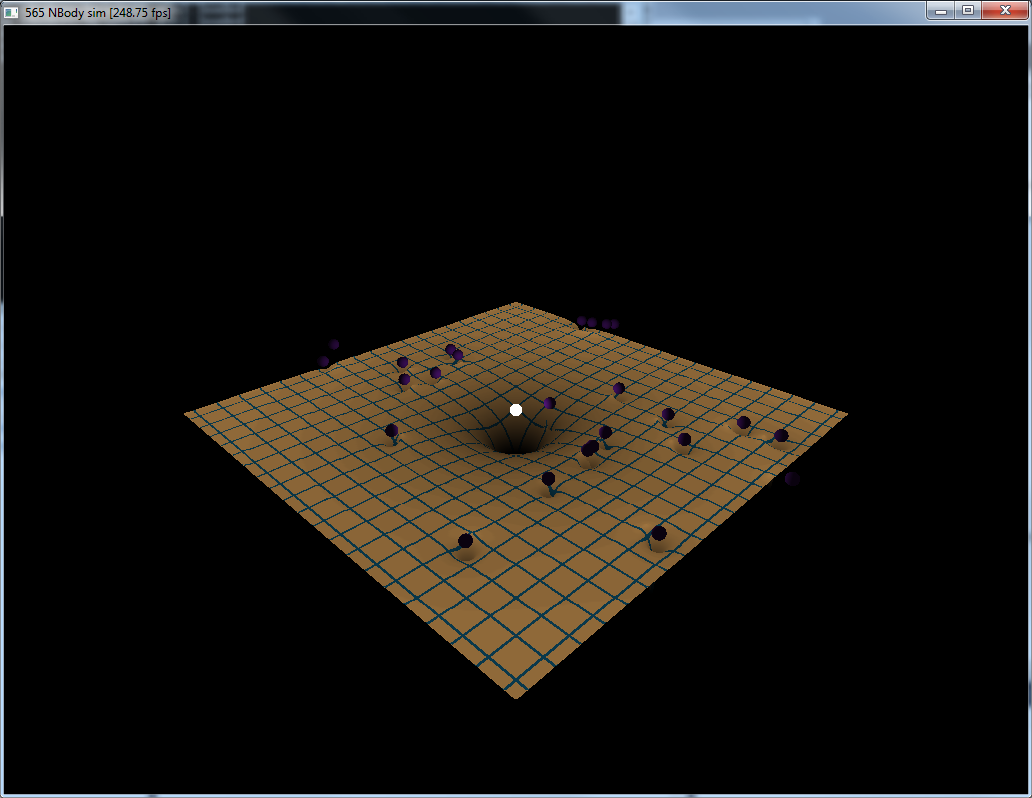

In this project, the positions, velocities and accelerations of all objects are stored in global memory locations dev_pos, dev_vel and dev_acc respectively. I was required to write device functions to calculate the accelerations for every object using both the global memory and shared memory. As an added bonus, I was able to implement prefetching for shared memory (where instead of directly loading a value from global memory into shared, we pre-load into a register ahead of the current iteration and then load that into shared during the current iteration) and two other integration schemes: Verlet and Leapfrog (a Symplectic Euler integrator was provided by default).
In addition to the above, I was also required to do my own simulation. I implemented dynamic flocking, where planets dynamically drop in and out of flocks. Such flocks are created on the fly as planets move around. This dynamic flocking runs when the command line parameter is set to 'true'.
Performance of the program was compared for different number of planets/objects being simulated, using global memory, shared
memory and prefetched version of shared memory. Here are the results:
With visualization on:
| Memory type | Number of objects | Framerate | Number of objects | Framerate |
|---|---|---|---|---|
| Global | 2500 | 1.75 | ||
| Shared | 2500 | 12 | 5000 | 6.77 |
| Shared (Prefetched) | 2500 | 12 | 5000 | 6.77 |
5000 objects were not simulated in global memory since the framerate was close to 0.
With visualization off:
| Memory type | Number of objects | Framerate (avg.) | Number of objects | Framerate (avg.) |
|---|---|---|---|---|
| Global | 1,500,000 | 53 | 3,000,000 | 53 |
| Shared | 1,500,000 | 615 | 3,000,000 | 620 |
| Shared (Prefetched) | 1,500,000 | 630 | 3,000,000 | 630 |
| Global | 5,000,000 | 53 | 10,000,000 | 53 |
| Shared | 5,000,000 | 630 | 10,000,000 | 615 |
| Shared (Prefetched) | 5,000,000 | 630 | 10,000,000 | 615 |
| Global | 20,000,000 | 53 | 50,000,000 | 53 |
| Shared | 20,000,000 | 620 | 50,000,000 | 620 |
| Shared (Prefetched) | 20,000,000 | 615 | 50,000,000 | 630 |
These results show that shared memory is WAY better than global memory. As I mentioned above, if the bank conflicts resulting out of threads accessing multiple shared memory locations were to be corrected, the program would run much faster.
The results also show no great advantage while using prefetching. I believe this is because there are not many independent instructions to mask out the latency involved in accessing global memory.